최고의 AI가 26.6%밖에 풀지 못한 인류 최후의 시험
최고의 AI가 26.6%밖에 풀지 못한 인류 최후의 시험 (Humanity’s Last Exam, HLE)
오픈AI가 새롭게 공개한 ‘딥 리서치(deep research)’ 기능은 AI가 직접 정보를 조사하고 분석하여 보고서 형태로 제공하는 기술입니다. (관련 소식) 하지만, 이 딥 리서치 기능도 최근 선보인 ‘인류 최후의 시험 (Humanity’s Last Exam, HLE)’ 이라는 시험에서는 고작 26.6% 밖에 정답을 맞히지 못했다고 합니다. 최신 AI들이 기존 벤치마크(MMLU 등)에서는 90% 이상의 정답률을 기록하며 놀라운 성능을 보였던 것과 비교하면 상당히 낮은 수치입니다. 대체 이 시험은 무엇이고, 어떠한 방식으로 AI의 한계를 시험하는 것일까요?

- 논문: https://arxiv.org/abs/2501.14249
- Illuminate 팟 캐스트: HLE의 논문을 팟캐스트 형식으로 들을 수 있습니다.
인류 최후의 시험(HLE)의 특징과 목표
HLE는 단순히 “어려운 문제”만 내는 시험이 아닙니다. 인간이 오랫동안 쌓아 온 지식의 깊은 영역에서 AI가 얼마나 치밀하게 사고하고 분석할 수 있는지를 평가하는 것이죠. 수학, 인문학, 자연과학 등 100개 이상의 다양한 분야에서 무려 3,000개의 문제가 출제되며, 단순 검색으로 답을 찾기 어려운 형태로 구성되어 있습니다.
HLE 공식 사이트를 통해 논문과 시험 샘플을 살펴보실 수 있으며, 문제 유형은 고대 철학부터 퀀텀 컴퓨팅, 생태학, 언어학 등 정말 광범위합니다.
 출처: https://lastexam.ai/
출처: https://lastexam.ai/
가장 인기 있는 50개 학문 분야: 수학, 물리학, 컴퓨터 과학, 화학, 응용 수학, 상식, 전기 공학, 생물학, 언어학, 의학, 유전학, 역사, 경제학, 생태학, 인공지능, 음악학, 철학, 신경과학, 법학, 미술사, 생화학, 천문학, 고전학, 체스, 화학 공학, 미생물학, 클래식 발레, 재료과학, 시학, 양자 역학, 항공우주 공학, 토목 공학, 기계 공학, 지리학, 로봇 공학, 데이터 과학, 분자 생물학, 통계학, 면역학, 교육학, 논리학, 계산 생물학, 심리학, 영문학, 기계 학습, 퍼즐, 문화 연구, 해양 생물학, 고고학, 생물물리학.
HLE는 각 분야의 전문가들이 공동 개발한 시험으로, 객관식(MCQ) 및 단답형(SAQ) 문제로 구성되어 있어 자동 채점이 가능합니다. 모든 문제는 명확한 정답이 존재하며, 쉽게 검증할 수 있지만 단순한 인터넷 검색으로는 답을 찾을 수 없도록 설계되었습니다. 즉, AI가 단순한 정보 검색이 아닌 깊은 사고와 논리적 분석을 통해 해결해야 하는 문제들이라는 점이 특징입니다.
실제 문제 예시
HLE 문제는 기존 벤치마크와 비교해 훨씬 까다롭습니다. 다음은 논문에 소개된 HLE 문제들 예제입니다.
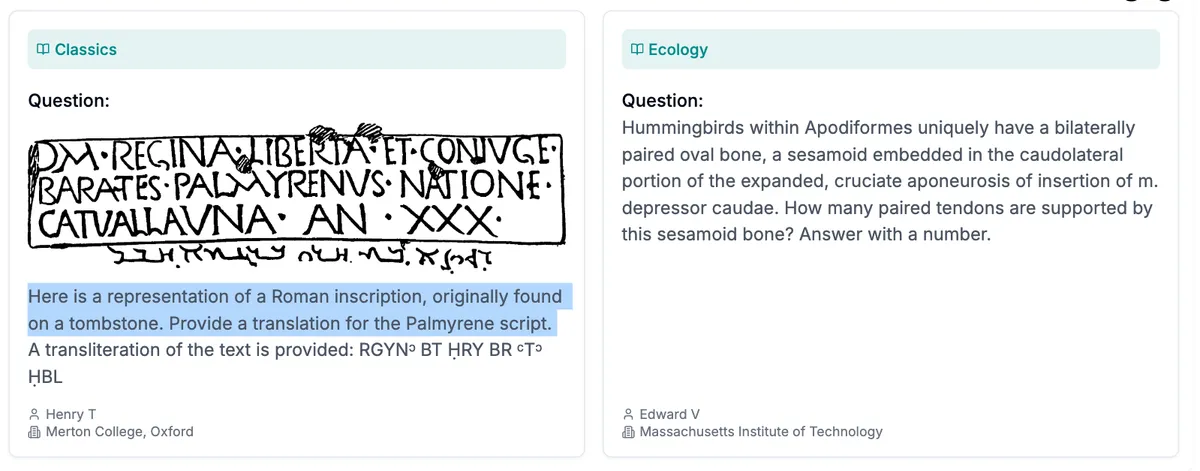
- 고전과 생태학
- 고전: 다음은 로마 비문을 나타낸 것으로, 원래는 묘비에서 발견된 것입니다. 팔미라 문자로 된 내용을 번역하세요. 해당 텍스트의 음역(transliteration)은 다음과 같습니다: RGYNᵓ BT ḤRY BR ᶜTᵓ ḤBL
- 생태학: 칼새목(Apodiformes)에 속하는 벌새는 독특하게도 양쪽에 쌍을 이루는 타원형 뼈를 가지고 있으며, 이는 꼬리 내림근(m. depressor caudae)의 확장된 십자형 건막(cruciate aponeurosis of insertion) 후외측 부분에 박혀 있는 종자골(sesamoid)입니다. 이 종자골이 지지하는 쌍을 이루는 힘줄의 개수는 몇 개인가요? 숫자로 답하세요.
- 수학 및 컴퓨터 과학

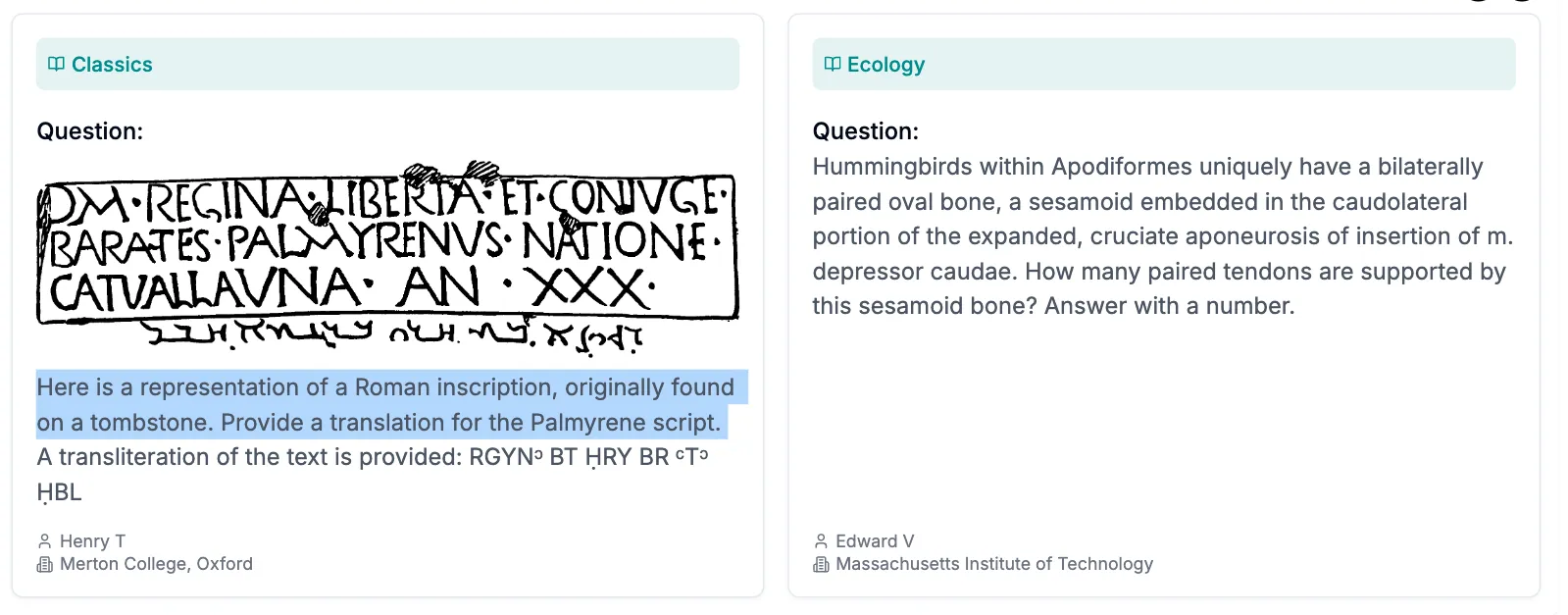
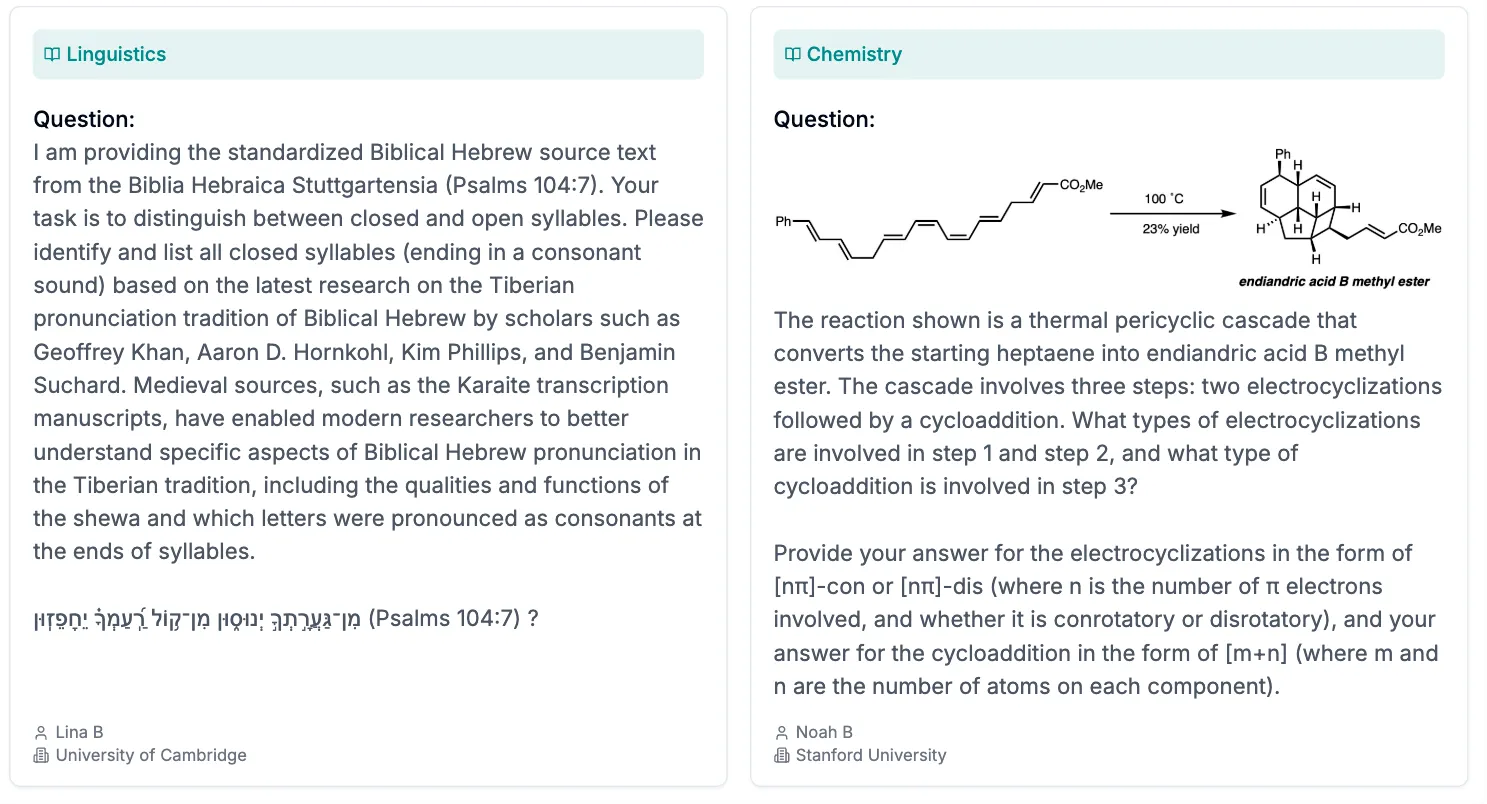
- 언어학과 화학
- 언어학: 나는 Biblia Hebraica Stuttgartensia에서 제공하는 표준 성경 히브리어 원문(시편 104:7)을 제공합니다. 당신의 과제는 닫힌 음절(자음으로 끝나는 음절)과 열린 음절(모음으로 끝나는 음절)을 구별하는 것입니다… 주어진 구절:
- מִן־גַּעֲרָ֣תְךָ֣ יְנוּס֑וּן מִן־ק֥וֹל רַֽ֝עַמְךָ֗ יֵחָפֵזֽוּן (시편 104:7)
- 화학: 제시된 반응은 열적 퍼리사이클릭 연쇄 반응으로, 시작물질인 헵타엔(heptaene)을 엔디안드릭산 B 메틸 에스터(Endiandric acid B methyl ester)로 전환합니다… 그리고 3단계에서 어떤 유형의 첨가 반응(cycloaddition)이 발생하는지 설명하세요.
이처럼 단순한 지식 암기가 아닌, 심층적인 분석과 논리 전개 능력을 요구하는 형태라서 쉽게 풀기 어려운 문제들입니다.
최신 AI 성능: 26.6%의 정확도
최근 오픈AI가 공개한 딥 리서치(deep research) 모델이 HLE에서 기록한 단, 정답률은 26.6%. 기존에 여타 벤치마크 시험에서 90% 이상을 기록하던 AI 모델들이었다는 점을 떠올리면, 이 수치는 확실히 낮아 보입니다.
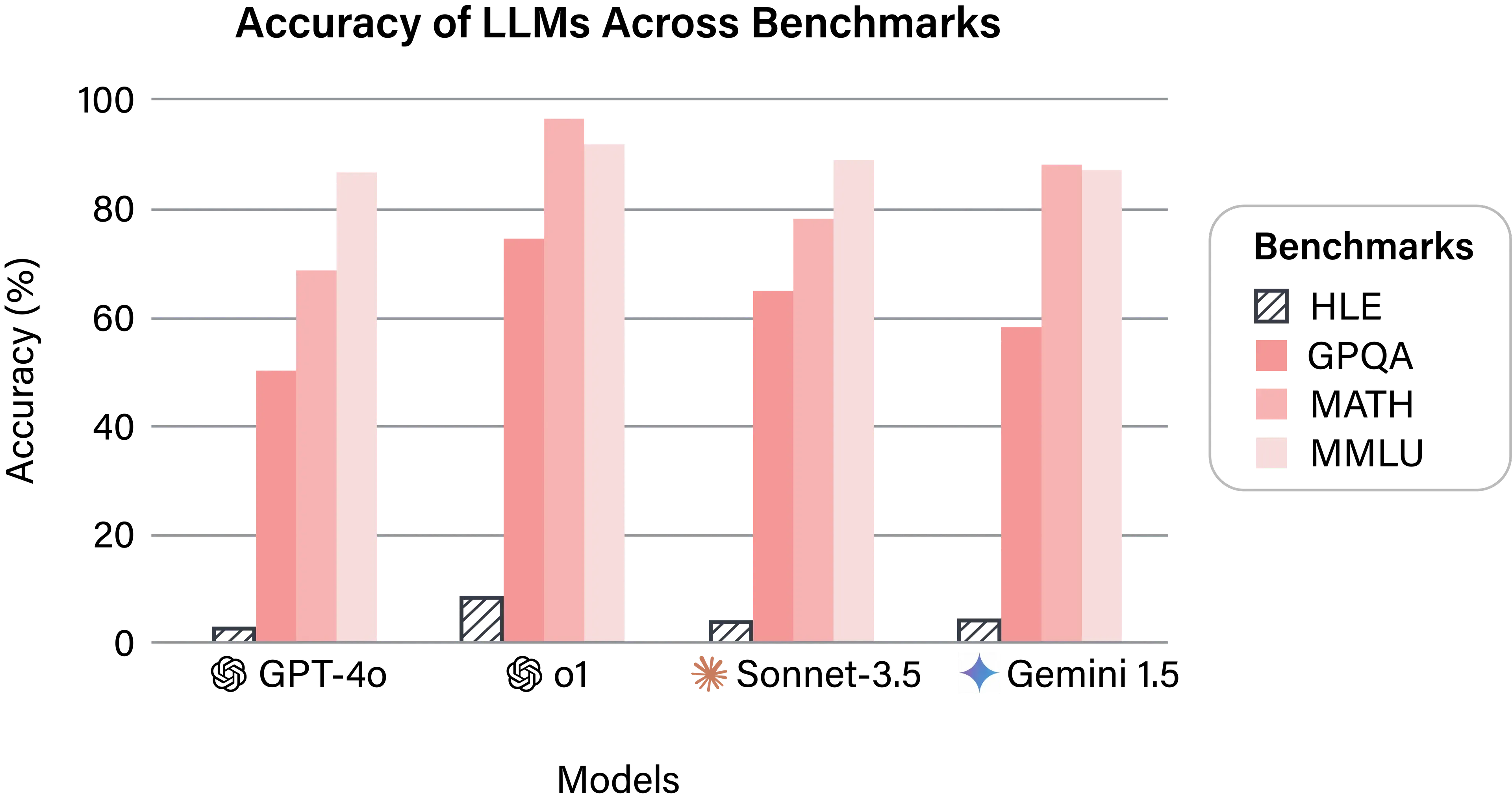
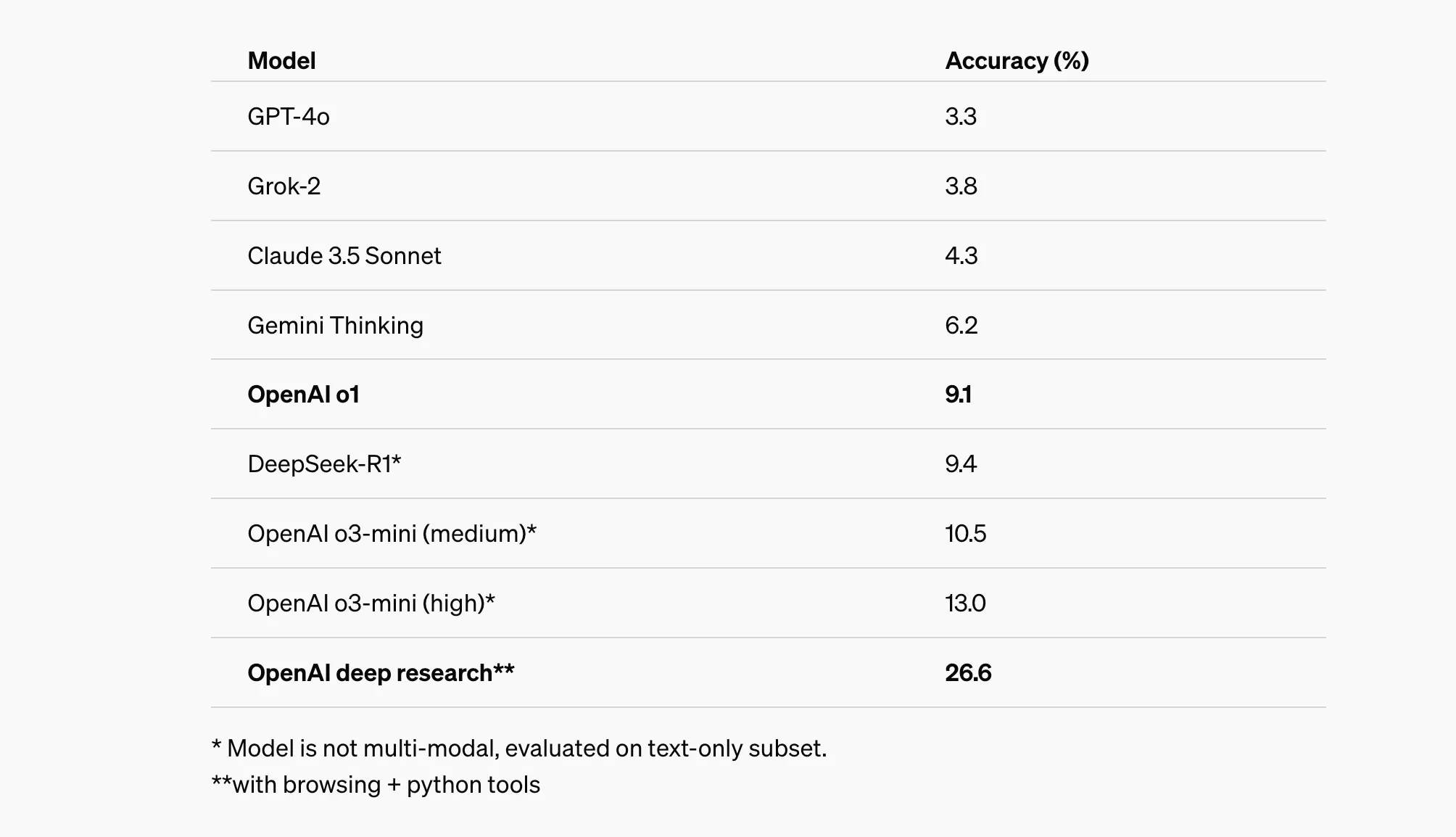
- 출처: 논문 및 OpenAI
- deep research(26.6%) vs. DeepSeek-R1(9.4%)
딥 리서치 모델은 이전 버전보다 3배 가까이 높은 성능을 보여주었지만, 아직도 인간 전문가 수준에는 거리가 있습니다. - 복잡한 정보 탐색 능력
딥 리서치 모델은 단순 검색을 넘어 전문 연구자처럼 사고를 확장한다는 면에서 주목받고 있으나, 전문 분야에서 요구되는 깊은 지식과 논리성을 완벽히 구현하기엔 부족한 점이 여전히 있습니다.
HLE가 갖는 의미
HLE는 앞으로 AI 기술이 나아가야 할 방향을 제시하는 중요한 기준이 될 것이라는 평가를 받습니다. 연구자들은 가까운 시일 내에 AI 정답률이 50%를 넘길 수 있다고 전망하면서도, 그 순간이 곧바로 인간 수준의 일반 지능(AGI) 달성을 의미하는 것은 아니라고 강조합니다.
또한, HLE는 시험 문제와 데이터셋을 꾸준히 업데이트하며, 공개 검토 기간도 계획하고 있어 시험 자체의 완성도를 높이려 노력하고 있습니다. 이는 AI가 인간의 지적 능력을 어디까지 따라잡을 수 있는지 확인하는 유의미한 실험이 될 것으로 보입니다.
인간과 AI의 지적 경계를 가늠하다
3,000여 개에 달하는 HLE 문제는 지금껏 많은 벤치마크를 우수한 성적으로 통과해 온 AI에게도 또 다른 도전입니다. 26.6%라는 성적은 분명 아쉬워 보이지만, 동시에 앞으로의 발전 가능성을 엿보게 해줍니다. 실제로 AI 기술은 매우 빠른 속도로 진화하는 중이니, 머지않아 또 다른 놀라운 결과를 보여줄 수 있을지도 모르죠.
허깅페이스에 공개된 HLE 문제 살펴보기
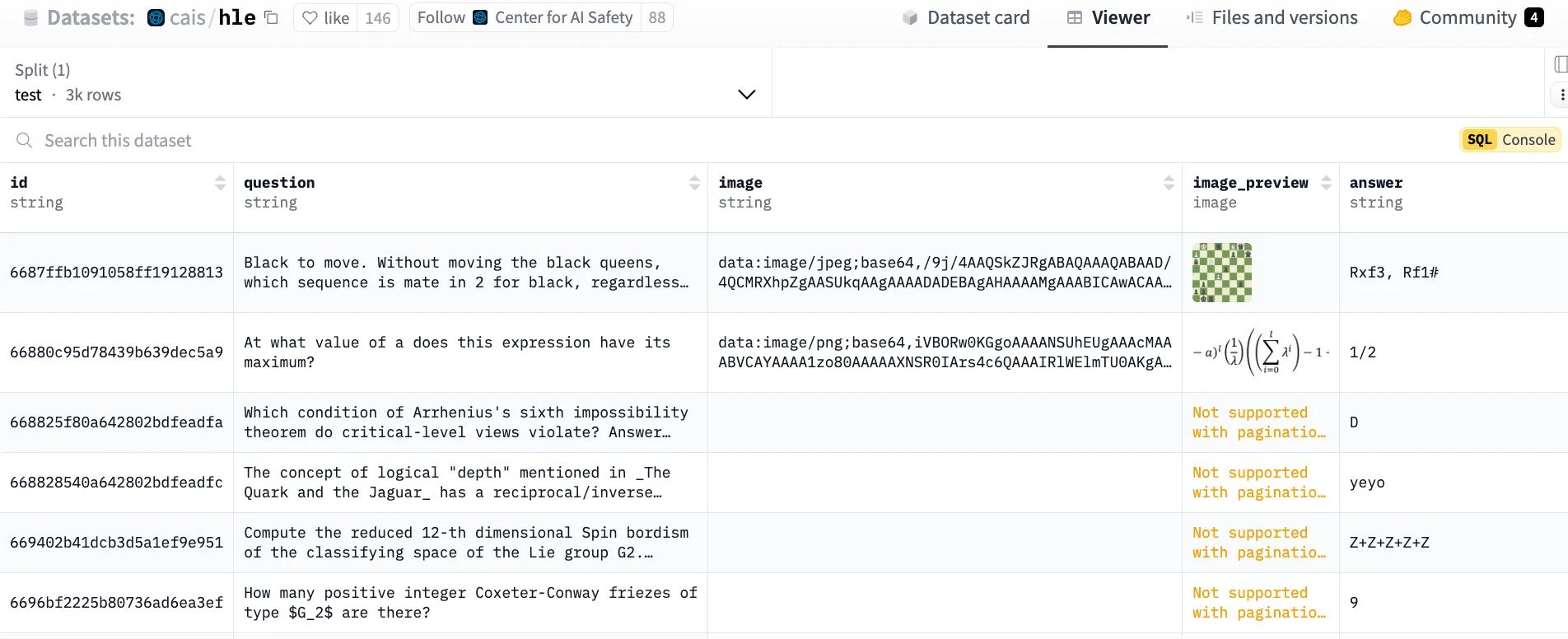 사진: 허깅페이스에 소개된 문제들
사진: 허깅페이스에 소개된 문제들
결국, HLE는 단순한 시험이 아니라 AI가 인간 수준의 깊은 사고에 얼마나 접근할 수 있는지 판단하는 기준점으로 떠오르고 있습니다. 앞으로 이어질 기술적 진보를 지켜보며, 우리가 인간의 지적 능력과 AI의 협업 가능성을 어디까지 확장해 갈지 기대해 보는 것도 흥미로운 일일 것입니다.




댓글
댓글 입력창이 안 보이면, 새로 고침을 눌러 주세요.