생성형 AI 개녑들
생성형 AI 에서 자주 등장하는 용어들
거대 언어 모델 (Large Language Model, LLM)
거대 언어 모델(Large Language Model, LLM)은 방대한 양의 텍스트 데이터를 학습하여 인간과 유사한 텍스트를 생성하는 인공지능 모델입니다. 자연어 처리(NLP) 분야에서 혁신적인 발전을 가져왔으며, 챗봇, 번역, 콘텐츠 생성 등 다양한 애플리케이션에 활용됩니다. 대표적인 예시로는 챗GPT, 제미나이, 클로드 등이 있습니다.
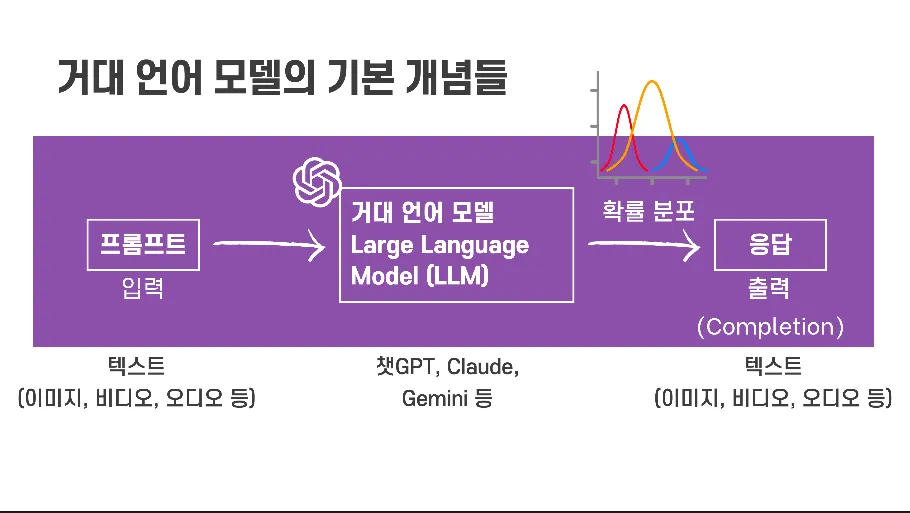
프롬프트 (Prompt)
거대 언어 모델 (LLM)에게 주어 적절한 응답을 유도하거나 “이끌어(elicit)”내는 텍스트로, 보통 질문이나 지시문 형태로 작성합니다.
예를 들면 다음과 같습니다.
- 프롬프트 엔지니어링이 뭐지?
- 챗GPT에 대해 알려 줘.
토큰 (Token)
토큰은 언어 모델이 텍스트를 처리할 때 사용하는 기본 단위입니다. 일반적으로 단어의 일부로 구성되며, LLM의 토크나이저(tokenizer)에 따라 다른 방식으로 표현됩니다.
영어의 경우, 약 0.75단어가 1토큰으로 간주됩니다. 예를 들어, “We’re learning about AI.”라는 문장은 GPT-4o의 경우, 총 6개의 토큰으로 나뉩니다.

환각 현상 (Hallucination)
환각 현상은 거대 언어 모델이 사실과 다르거나 존재하지 않는 정보를 마치 실제인 것처럼 생성하는 현상입니다. 모델이 학습 데이터에서 패턴을 학습하지만, 때로는 잘못된 정보를 만들어낼 수 있습니다. 이로 인해 사용자는 오해하거나 잘못된 판단을 내릴 수 있습니다.
검색 증강 생성 (Retrieval Augmented Generation, RAG)
검색 증강 생성은 거대 언어 모델이 외부 정보를 검색하여 답변 생성에 활용하는 기술입니다. 최신 정보를 반영하고 환각 현상을 줄이는 데 도움을 줍니다. 사용자의 질문에 대해 더 정확하고 신뢰할 수 있는 답변을 제공할 수 있습니다.
챗GPT를 사용하면서, 파일을 업로드 하거나, 챗GPT의 검색 중 인터넷 검색 결과를 함께 보신 적이 있으신가요? 그러면 이 검색 증강 생성 기술을 사용하고 계신 것입니다.
생각의 사슬 (Chain-of-Though, CoT), Think Step-by-Step
생각의 사슬 (사고의 고리, Chain-of-Thought, CoT)은 모델이 복잡한 문제를 해결할 때 단계별 추론 과정을 통해 논리적이고 체계적으로 답을 도출하는 방법론입니다. 이 기법은 모델에게 여러 단계의 사고를 요구하여 보다 정확하고 이해 가능한 결과를 제작하는 데 사용됩니다.
최신 모델에서는 기본적인 생각의 사슬 과정이 포함되어서 진행이 됩니다.
예를 들어:
“식료품점에서 사과 3개에 500원, 바나나 2개에 400원일 때, 사과 1개와 바나나 1개를 사면 총 얼마일까? (차근 차근 생각해 줘 / Think Step-by-Step).”
모델은 다음과 같이 단계별로 추론할 수 있습니다.
- 사과 3개의 가격이 500원이므로, 사과 1개의 가격은 500 / 3 = 약 167원입니다.
- 바나나 2개의 가격이 400원이므로, 바나나 1개의 가격은 400 / 2 = 200원입니다.
- 따라서 사과 1개와 바나나 1개의 총 가격은 167 + 200 = 367원입니다.
관련 자료
- [2201.11903] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | Arxiv
- Learning to reason with LLMs | OpenAI
제로샷 (Zero-shot), 퓨샷 (Few-shot)
제로샷은 모델이 특정 유형의 작업에 대한 예시 없이도 수행할 수 있는 능력을 의미합니다. 퓨샷은 모델이 몇 가지 예시를 통해 새로운 작업을 학습하고 수행하는 능력을 말합니다. 이러한 능력은 모델의 일반화 능력을 보여줍니다.
거대 언어 모델 파라미터
챗GPT 웹이나 앱을 통해 접근하는 일반 사용자들에게는 드러나지 않는 설정이지만, 거대 언어 모델의 동작을 제어하는 추가적인 파라미터들이 있습니다. 일반 사용자들에게 적절하게 최적의 값으로 조정되어 있다고 추측할 수 있짐나, 추가적인 동작의 제어가 필요하다면, API나 프로그래밍 접근을 통해 사용자가 원하는 대로 더 세밀하게 설정할 수 있습니다.
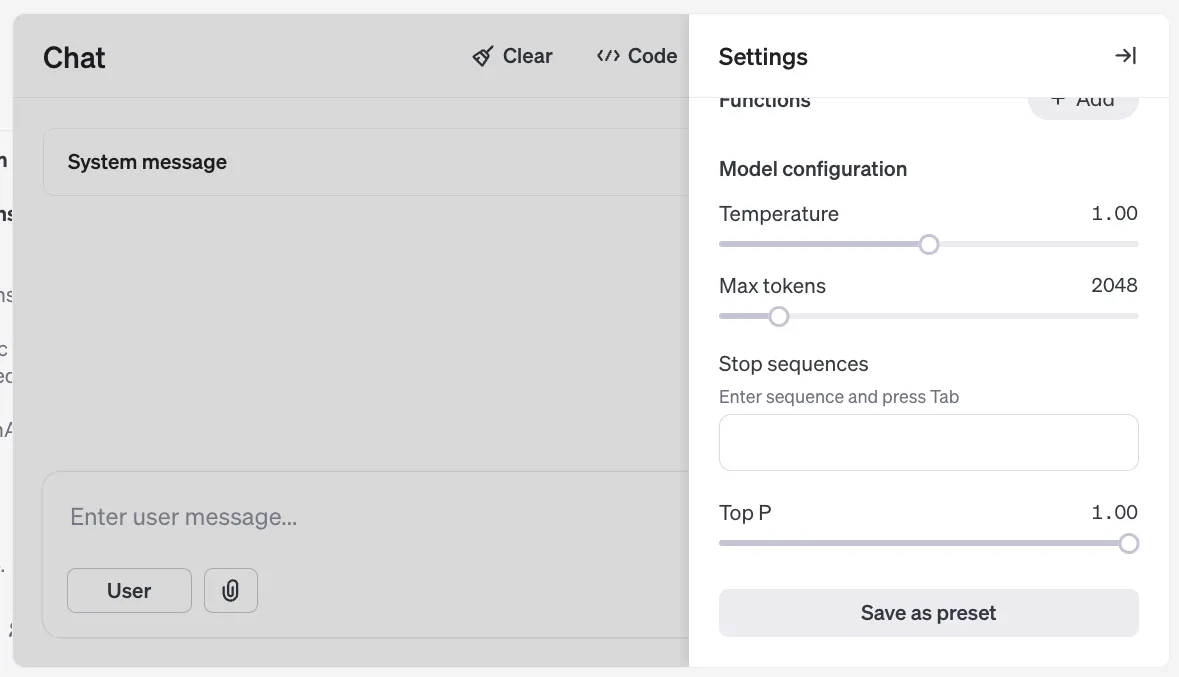
온도 (Temperature)
온도는 모델의 출력의 무작위성을 조절하는 파라미터입니다. 낮은 온도는 모델이 가장 가능성이 높은 단어를 선택하게 하여 예측 가능하고 결정적인 응답을 생성합니다. 높은 온도는 모델이 더 다양하고 창의적인 응답을 생성하도록 유도하지만, 일관성이 떨어지거나 오류가 발생할 가능성이 높아집니다.
탑-p (Top-p)
탑-p 샘플링은 확률 분포에서 누적 확률이 p를 넘지 않는 가장 가능성이 높은 토큰들의 집합 내에서 다음 토큰을 선택하는 방식입니다. 이 방식을 통해 모델은 너무 가능성이 낮거나 관련 없는 단어를 선택하는 것을 방지하고, 동시에 적절한 수준의 다양성을 유지할 수 있습니다. 온도를 조절하는 것과 유사하게 모델의 출력의 무작위성과 예측 가능성 사이의 균형을 맞추는 데 사용됩니다.



댓글
댓글 입력창이 안 보이면, 새로 고침을 눌러 주세요.